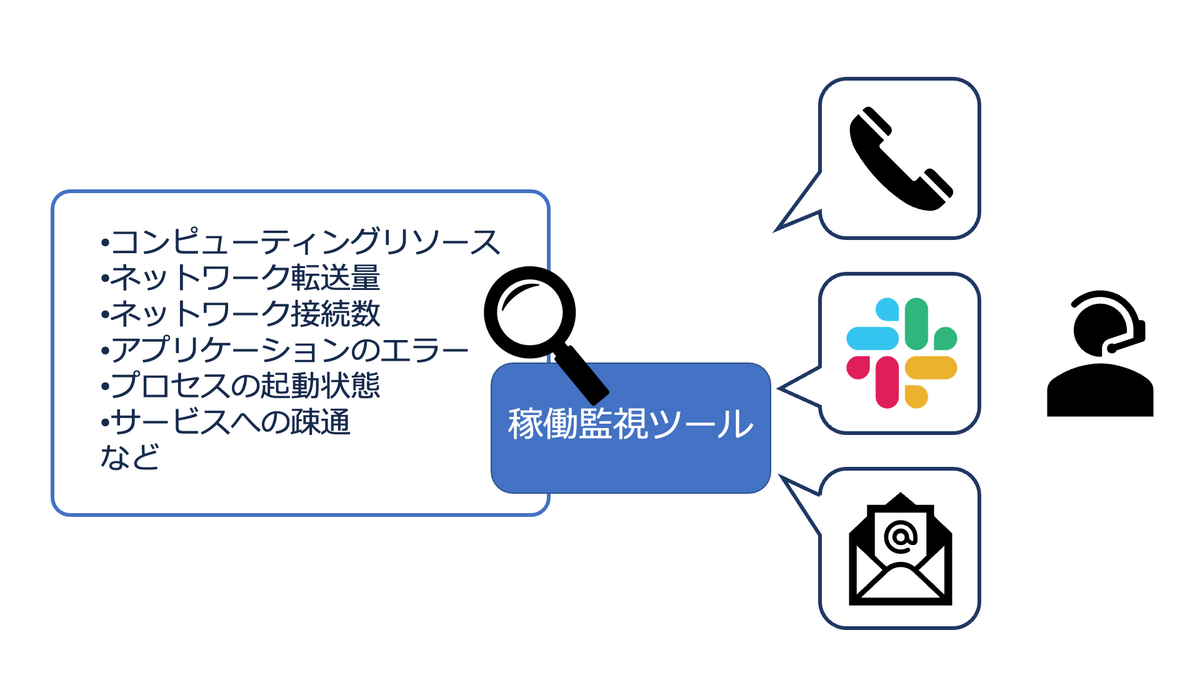
サービスはロールアウトしたらそれで終わりではなく、正しく稼動しているかを継続して監視する必要があります。
監視する項目はシステムによって様々ですが、主に
- 使用しているCPU・メモリ・ストレージなどのリソース
- ネットワーク転送量
- ネットワーク接続数
- アプリケーションのエラー
- プロセスの起動状態
- サービスへの疎通
などが挙げられます。
こうした項目を監視するのが、モニタリングシステムです。モニタリングシステムとしては、オープンソースソフトウェアのZabbixやPrometheus、SaaSのDatadogやMackerelなどが有名です。
またAWSやGCPは、クラウドベンダーに固有のモニタリングシステムを持っています。クラウドはその構成上、一般的なモニタリングツールでは必要な情報を取得し切れないことも多く、こうしたプラットフォームに応じたモニタリングシステムを併用することも重要です。
異常を検知したら、モニタリングシステムは運用担当者へ通知を行います。モニタリングシステムはメール、Slack、電話など、様々な通知手段を備えているのが一般的となっています。
また異常が発生していなくとも、サービスが使用しているリソースを把握しておくことは重要です。ユーザー数の増加により、ある日突然システムがダウンするといったことも起こり得ます。こうしたトラブルを未然に防ぐためには、普段からシステムの状態を分析しておく必要があります。そのためモニタリングシステムには、監視したデータを時系列にグラフ化する機能を備えているのが一般的です。