先日、第8回とことんDevOps勉強会でNominated Nodeよくわからんっと言ったら社長が色々調べてくれたので、こちらも再現手順など確認していきます。
とことんDevOps勉強会のイベントレポートは以下
NOMINATED NODE???
kubectl get pods -o wideをすると、右から2番目に出てくる項目です。
ここにどのような値がセットされるのかは以下で説明されています。
Pod PがノードNのPodをプリエンプトした場合、ノードNの名称がPのステータスのnominatedNodeNameフィールドに設定されます。このフィールドはスケジューラーがPod Pのために予約しているリソースの追跡を助け、ユーザーにクラスターにおけるプリエンプトに関する情報を与えます。
Pod Pは必ずしも「指名したノード」へスケジューリングされないことに注意してください。Podがプリエンプトされると、そのPodは終了までの猶予期間を得ます。スケジューラーがPodの終了を待つ間に他のノードが利用可能になると、スケジューラーは他のノードをPod Pのスケジューリング先にします。この結果、PodのnominatedNodeNameとnodeNameは必ずしも一致しません。また、スケジューラーがノードNのPodをプリエンプトさせた後に、Pod Pよりも優先度の高いPodが来た場合、スケジューラーはノードNをその新しい優先度の高いPodへ与えます。このような場合は、スケジューラーはPod PのnominatedNodeNameを消去します。これによって、スケジューラーはPod Pが他のノードのPodをプリエンプトさせられるようにします。
以下、私の解釈
ノードの空きリソースに対してPodのリソース要求が多い場合、そのPodは待機状態となります。このPodを仮にPと呼びます。このPod Pより優先度の低いPodがあれば、そのPodをプリエンプト(強制的な一時中断)して、ノードNのリソースを確保しようとします。この時にPod Pの「NOMINATED NODE」にリソースを確保しようとしたノード名Nがセットされます。
「確保しようとした」とした理由
ノードNがPod PのNOMINATED NODEにセットされた後、ノードNの優先度の低いPodを終了している間、他のノード(仮にX)のリソースが空いた場合、スケジューラーはそちらのノードXにPod Pを割り当てる動作をします。必ずしもNOMINATED NODEに割り当てられたノードにデプロイされるとは限りません。
ためしてみる
今回もminikubeで試していきます。minikubeのインストールや使い方は以下を参考にしてください。
今回は以下のコマンドでノードを3つ用意してみます。minikubeは--profile <profile-name>で複数のプロファイルを切り替えて使えるので、ちょっとした実験なんかはこれで十分ですね。
minikube start --nodes 3 --profile nominated

Podのプライオリティを設定するにはPriorityClassオブジェクトが必要です。以下の3つのPriorityClassを用意していきます。
優先度高のPriorityClass
cat <<EOF | kubectl apply -f - apiVersion: scheduling.k8s.io/v1 kind: PriorityClass metadata: name: high-priority value: 1000000 EOF
優先度高だけどプリエンプションが発生しないPriorityClass。preemptionPolicy: Neverとすることでプリエンプションが発生しないらしいです。
cat <<EOF | kubectl apply -f - apiVersion: scheduling.k8s.io/v1 kind: PriorityClass metadata: name: high-priority-nonpreempting value: 1000000 preemptionPolicy: Never EOF
優先度低のPriorityClass
cat <<EOF | kubectl apply -f - apiVersion: scheduling.k8s.io/v1 kind: PriorityClass metadata: name: low-priority value: 100 EOF
次にPodを用意していきます。
まずは優先度低のPodをapp1という名前で作ります。優先度の設定は、先ほど作ったPriorityClassをpriorityClassName:にいれればOKです。
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: app1
name: app1
spec:
replicas: 10
selector:
matchLabels:
app: app1
template:
metadata:
labels:
app: app1
spec:
containers:
- image: nginx:1.23
name: app1
ports:
- containerPort: 80
resources:
requests:
memory: "500Mi"
cpu: "500m"
limits:
memory: "1Gi"
cpu: "1000m"
priorityClassName: low-priority
EOF
できあがったPodはこんな感じ。まだNOMINATED NODEは<none>のままです。
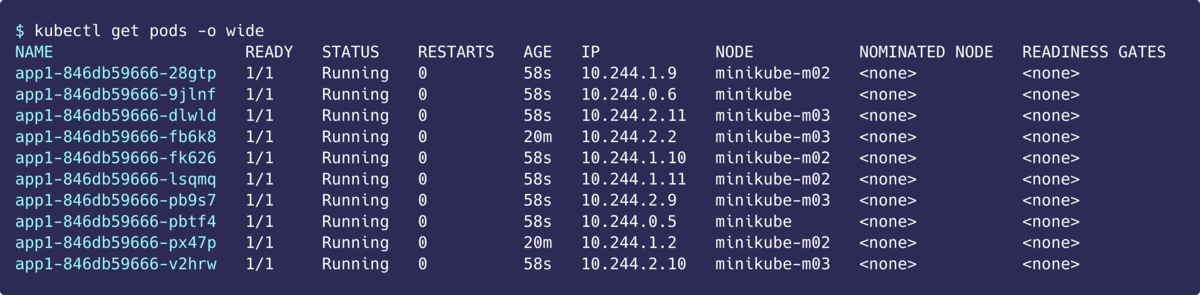
次に優先度高のPodをapp2という名前で作ります。
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: app2
name: app2
spec:
replicas: 10
selector:
matchLabels:
app: app2
template:
metadata:
labels:
app: app2
spec:
containers:
- image: nginx:1.23
name: app2
ports:
- containerPort: 80
resources:
requests:
memory: "500Mi"
cpu: "500m"
limits:
memory: "1Gi"
cpu: "1000m"
priorityClassName: high-priority
EOF
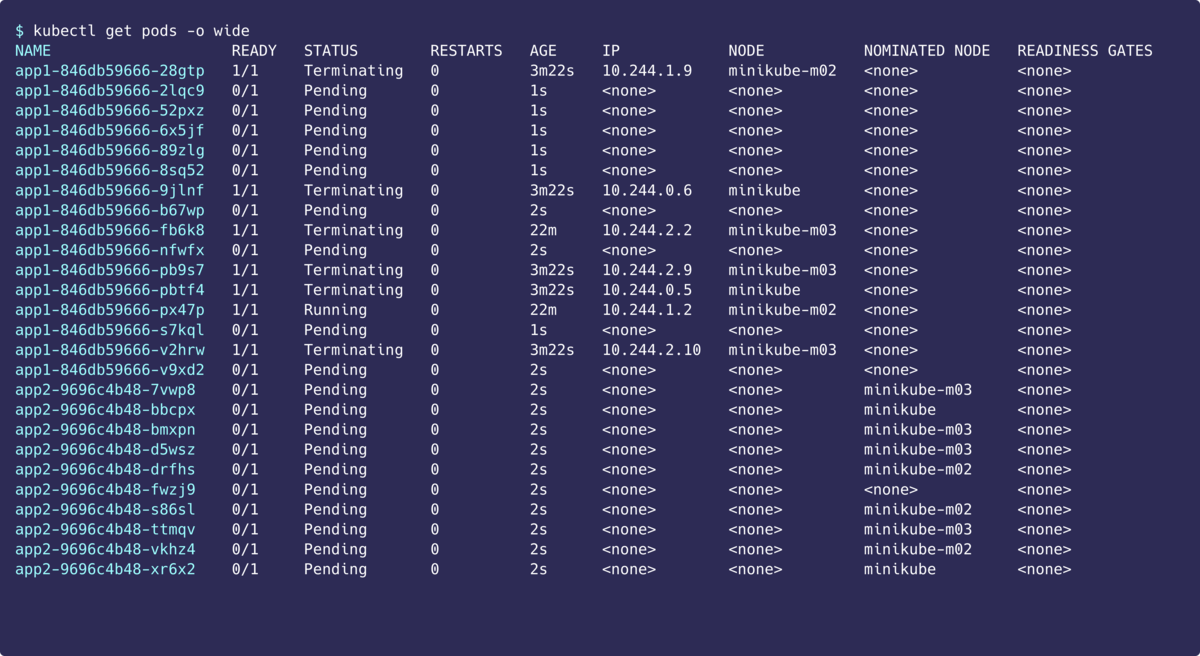
app1のいくつかのPodがTerminatingされていて、app2のNOMINATED NODEにノード名が入っていますね。
落ち着いたころに確認してみるとこんな感じでした。
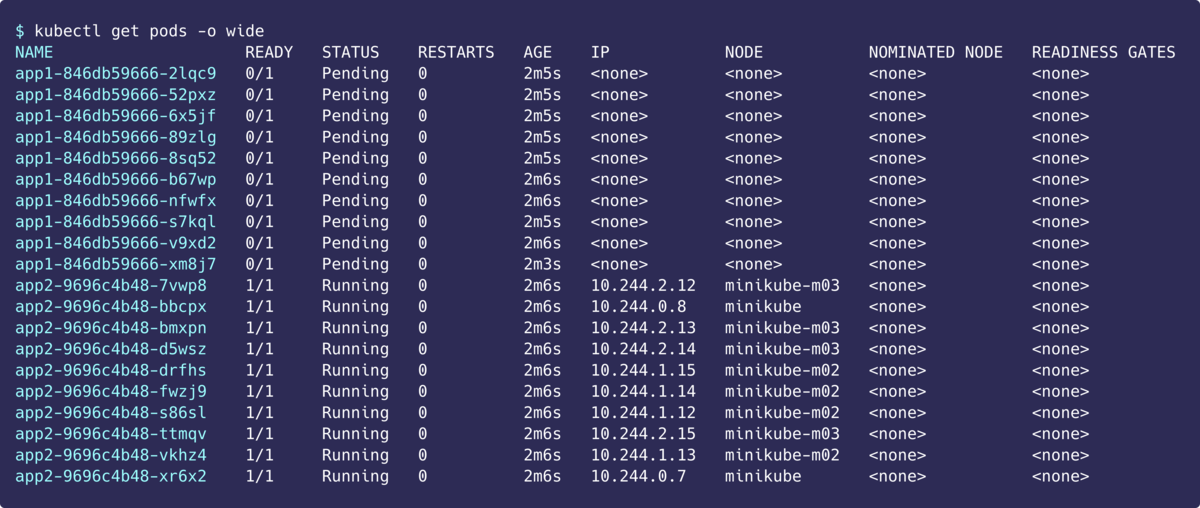
app2を削除すると、PendingになっていたPodが元に戻りました。
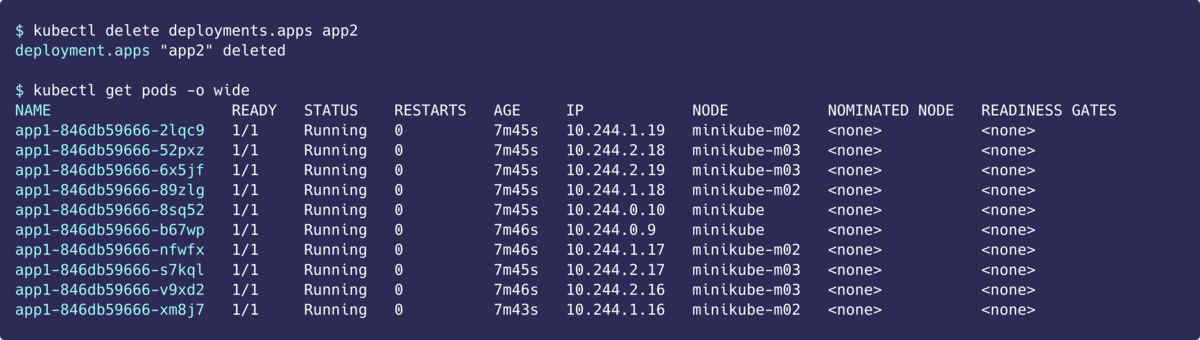
次は優先度高だけどpreemptionPolicy: Neverが設定されているPodをapp3という名前で作ります。preemptionPolicy: Neverが設定されているのでプリエンプションが発生しないはず……
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app3: app3
name: app3
spec:
replicas: 10
selector:
matchLabels:
app3: app3
template:
metadata:
labels:
app3: app3
spec:
containers:
- image: nginx:1.23
name: app3
ports:
- containerPort: 80
resources:
requests:
memory: "500Mi"
cpu: "500m"
limits:
memory: "1Gi"
cpu: "1000m"
priorityClassName: high-priority-nonpreempting
EOF
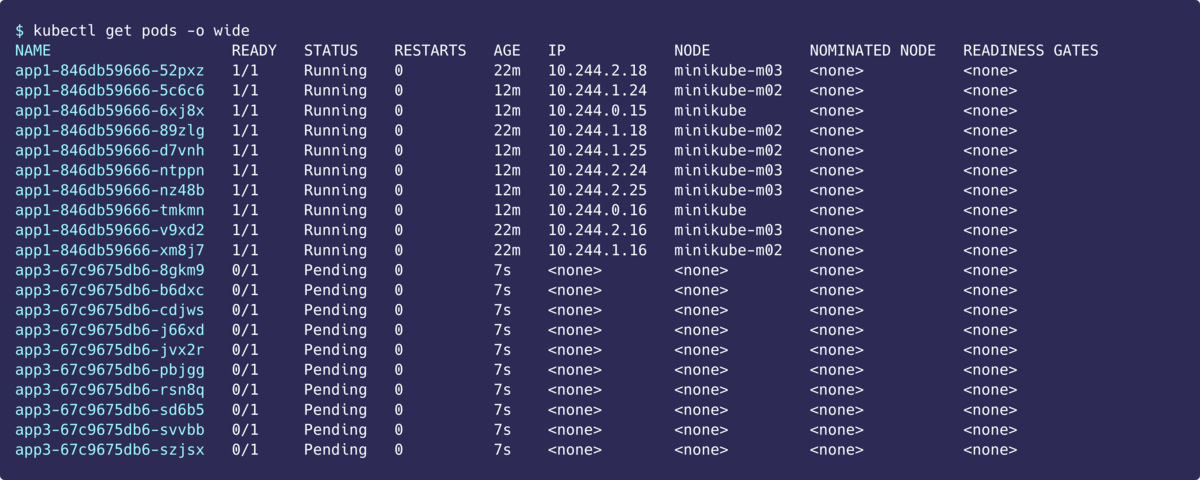
プリエンプションされてない!
っということで、preemptionPolicy: Neverの認識も間違っていなかったようですね。完全に理解しました。
