以前vLLMとGooseでローカルLLMコーディングの話を書きました。
これは任意のエディター、Gooseを介してSaaSのAIやローカルのAIを使ったLLMコーディングを実現すると言う話でした。
私はそこまで知らなかったのですが、VSCode使いであれば今のバージョンであればCopilotの標準機能を通じて、外部AIを使うことができるようになっているようです。 先週、こんな記事を見まして。
VS Code 1.117がリリースされ、GitHub Copilot Business/Enterpriseプランでも外部モデルを利用可能になったと言う記事でした。記事に書かれているように個人用のプランではすでに使えていたそうです。
利用できる外部モデルの中にOllamaがあったので、早速使ってみることにしました。
VSCodeで外部モデルを利用するには
VSCodeに外部モデルを追加するには、チャットを開いてモデル選択の中から、右上のカスタマイズボタン(⚙️)をクリックします。
するとモデル一覧が表示されますので、右上の「モデルを追加」をクリックして、その横に現れるプロバイダーから任意のプロバイダーを選びます。今回はOllamaを選んでみましょう。事前にOllamaのインストール、起動、Ollamaへのモデルのダウンロードを行ってから実施してください。
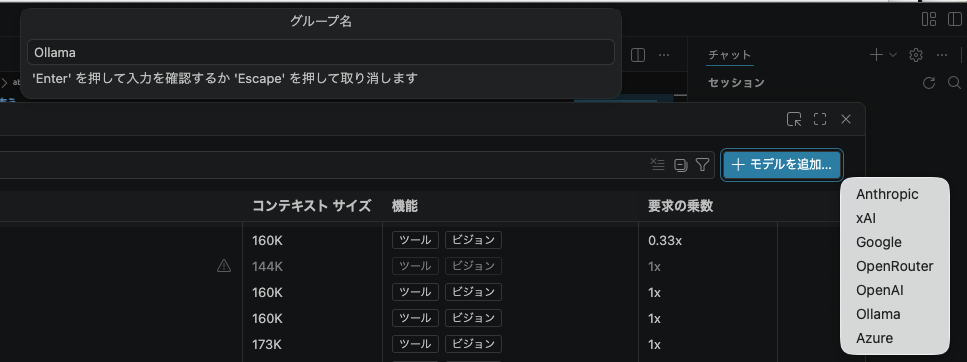
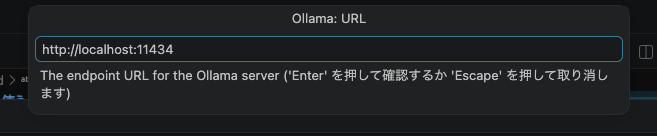
あとはグループ名とエンドポイントのアドレス(デフォルトはhttp://localhost:11434)を設定したら終わりです。
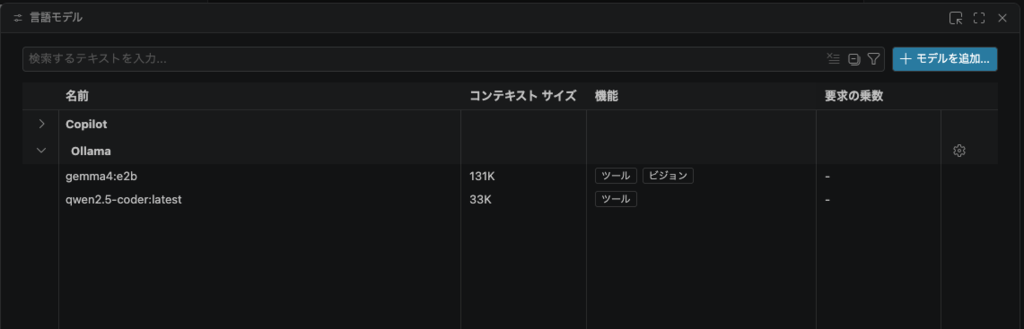
これで、GitHub Copilotが使えるモデルとして、Ollama Serverが追加されます。 Ollamaで追加したモデルはすぐ認識されて、VSCodeのGitHub Copilotで使えるようです。
これ自身は自分のマシン上で動いているので、どれだけ使っても無料です。
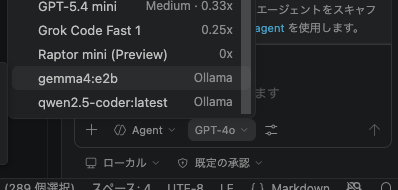
チャット画面では、モデルとして追加したOllamaに用意したモデルを選択すれば、ローカルLLMとCopilot Chatから対話できます。 またインラインチャットでローカルLLMのモデルをつかうことも可能です。
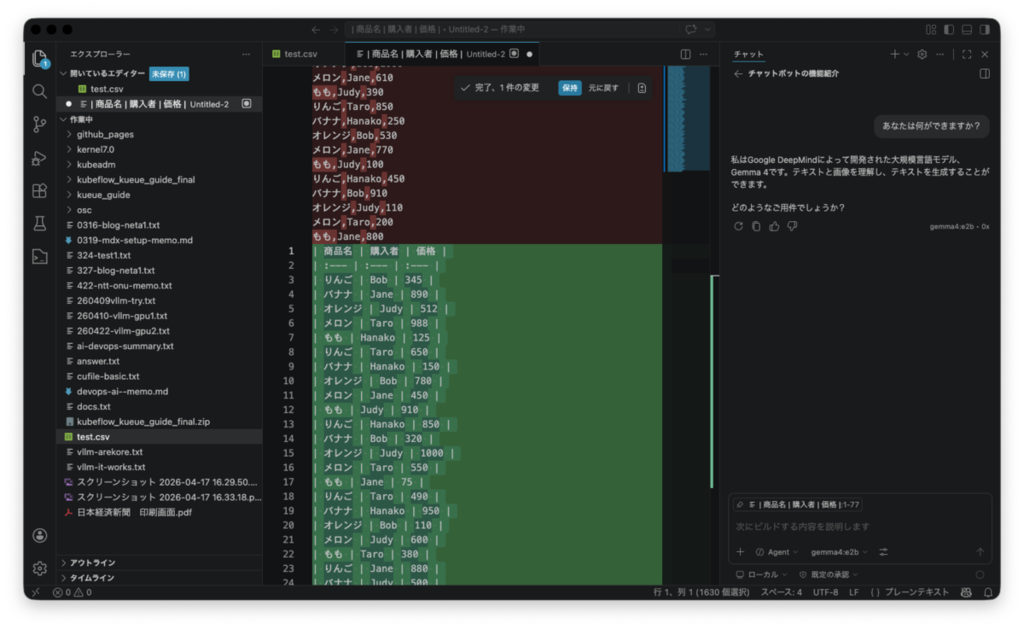
インラインチャットとは、右側でチャットを開いてがっつり対話するのと違って、ソースの一部を選択してインラインチャットを開いて、「この部分のソース部分のコードを構文チェックして」みたいなリクエストを行うときに使う機能です。
インラインチャットはデフォルトで「Auto」が設定されているので、私の場合は「Claude Sonnet 4.6」が利用するたびに使われていました。ここを任意のモデルに切り替えるとプレミアムリクエストの消費対策に良いです。
設定検索で「inlineChat.defaultModel」を検索すると、設定を見つけられます。 デフォルトは自動になっています。
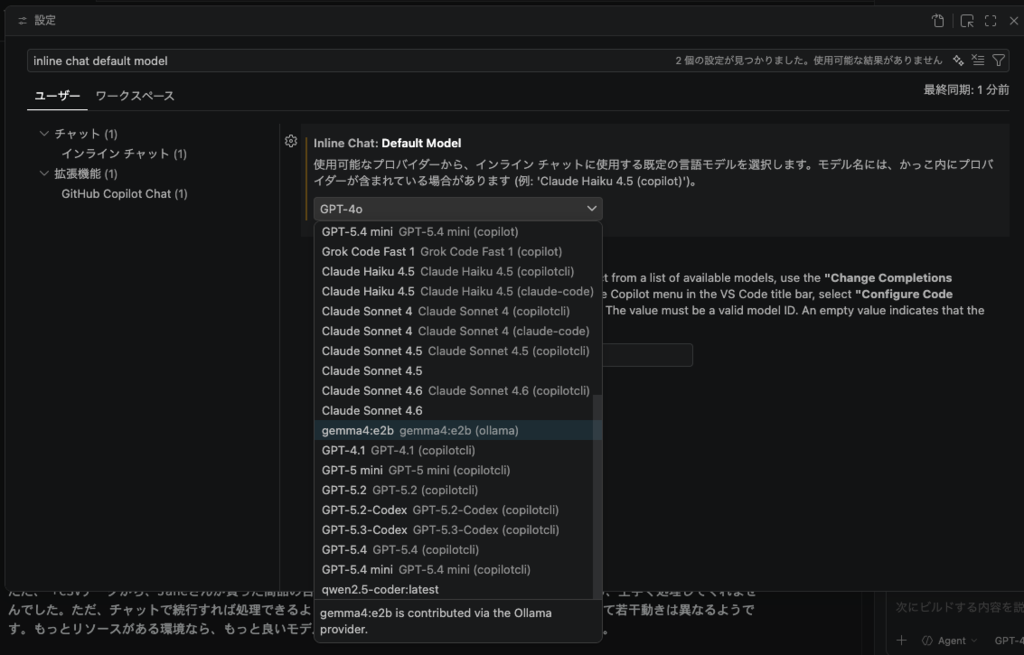
今回のお題はローカルLLMのOllamaを使うお題なので、追加したOllamaのモデルを使ってみます。
右側に表示されるCopilot Chatでモデルの選択でOllamaから提供されるモデルを選択すれば、当然ながらOllamaのLLMモデルと対話できます。 ソースを選択して右クリックし、「インラインチャットを開く」を実行すると、先ほど設定したモデルと対話しながらコードレビューしたり、コードの編集ができます。
たとえば普段私がよく使うのは、CSVファイルの内容を選択してインラインチャットを開き、「CSVデータをMarkdownの表形式にして」を実行してみると、良い感じに変更できました。
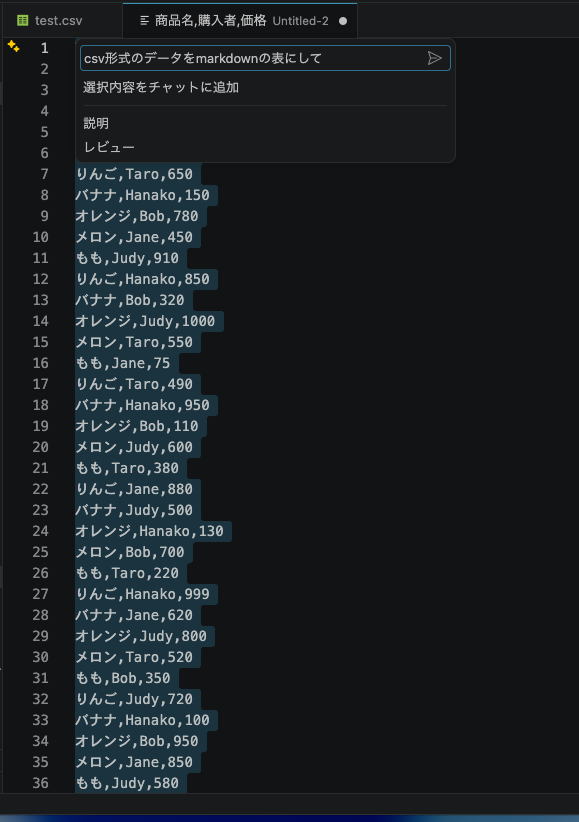
ただし、モデルは選ぶかも?
ただ、「CSVデータから、Janeさんが買った商品の合計をして、画面に合計を表示して」といったところ、インラインでは上手く処理してくれませんでした。ただ、チャットで続行すれば、処理できるようでした。ここら辺はモデルやプロバイダーによって若干動きが異なるようです。もっとリソースがある環境なら、もっと良いモデルを使ったら、結果が変わってくるかもしれません。
ちなみにこれくらいの内容であれば、GitHub Copilot Proでプレミアムリクエストを0x、つまり消費せずに使えるGPT 4.1とかGPT4oなどのモデルであれば、ちゃんと集計してVSCodeのソース部分に集計した結果を出力できました。
なお、GitHub Copilotは2026年6月1日より、課金体系に変更があるようです。 これまで0xで利用できていたモデルは6/1から課金対象になります。また、プレミアムリクエストという概念は無くなり、課金した分のクレジットを消費していくと言う感じになるようです。たとえばProを契約している場合、10ドル払って、10ドル分のクレジットを使った分だけ消費していくと言う流れです。Planの値上げはありませんが、モデルの利用料は実質上がっているので、あらかじめ注意が必要です。
VSCodeのインラインチャットを多用する人は「inlineChat.defaultModel」は自動から、別のものに切り替えておくのもいいかもしれません。 これ使えそうだなあと今回、改めて感じました。
まとめ
「ローカルLLMを構築する手間をかけるより、SaaSのAIを利用した方が早い」という意見もありますが、実務においては外部へ持ち出すことが許されない機密情報の扱いや、限られた予算内でのリソース配分といった現実的な課題が常に付きまといます。こうした場面で、手元のリソースで完結するローカルLLMは極めて有効な解決策となります。
実際にローカル環境で試行錯誤を繰り返すことは、一見遠回りに見えますが、その過程で直面する苦労があるからこそ、SaaSが提供するサービスの質の高さや利便性を正しく評価できるようになります。また、高度な推論を必要としない日常的なタスクをローカル側に逃がすことで、APIコストなどの支出を抑えるといった運用上の知恵も生まれます。最終的には、どちらか一方に依存するのではなく、両者の特性を深く理解した上で、状況に応じて柔軟に使い分けられる環境を整えておくことこそが、AIを最も賢く活用する道だと言えるでしょう。
在庫が復活したら、がっつりメモリーとストレージを積んだMac miniを買おうかなとか、現在お財布と相談しているところです。 それともM5を待ったほうが良いでしょうか。悩んでいるうちが楽しいので、今のうちに沢山考えておきます。
次回はVSCodeでvLLMのモデルを使う方法をご紹介する予定です。いくつか方法はあるのですが、Clineという拡張機能を使うのが最も簡単でした。次回ご紹介したいと思います。
